DuLeMon (Baidu Long-term Memory Conversation)
Introduced by Xu et al. in Long Time No See! Open-Domain Conversation with Long-Term Persona Memory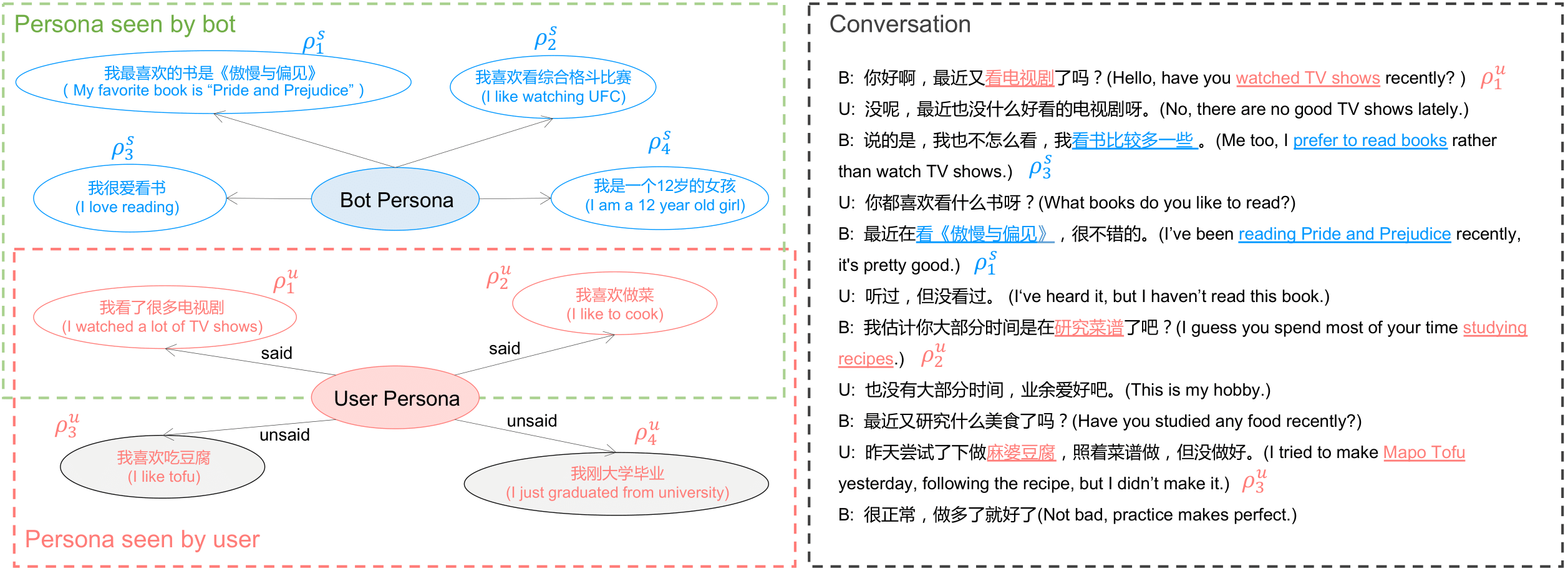
DuLeMon is a large-scale Chinese Long-term Memory Conversation dataset, which simulates long-term memory conversations and focuses on the ability to actively construct and utilize the user's and the bot's persona in a long-term interaction. DuLeMon contains about 27.5k human-human conversations, 449k utterances, and 12k persona grounding sentences. This corpus can be used to explore Long-term Memory Conversation, Personalized Dialogue, and Persona Extraction / Matching / Retrieval.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Dataset Loaders
No data loaders found. You can
submit your data loader here.
No data loaders found. You can
submit your data loader here.


