 Vision and Language Pre-Trained Models
Vision and Language Pre-Trained Models
BLIP: Bootstrapping Language-Image Pre-training
Introduced by Li et al. in BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and GenerationVision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner. Code, models, and datasets are released at https://github.com/salesforce/BLIP.
Source: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation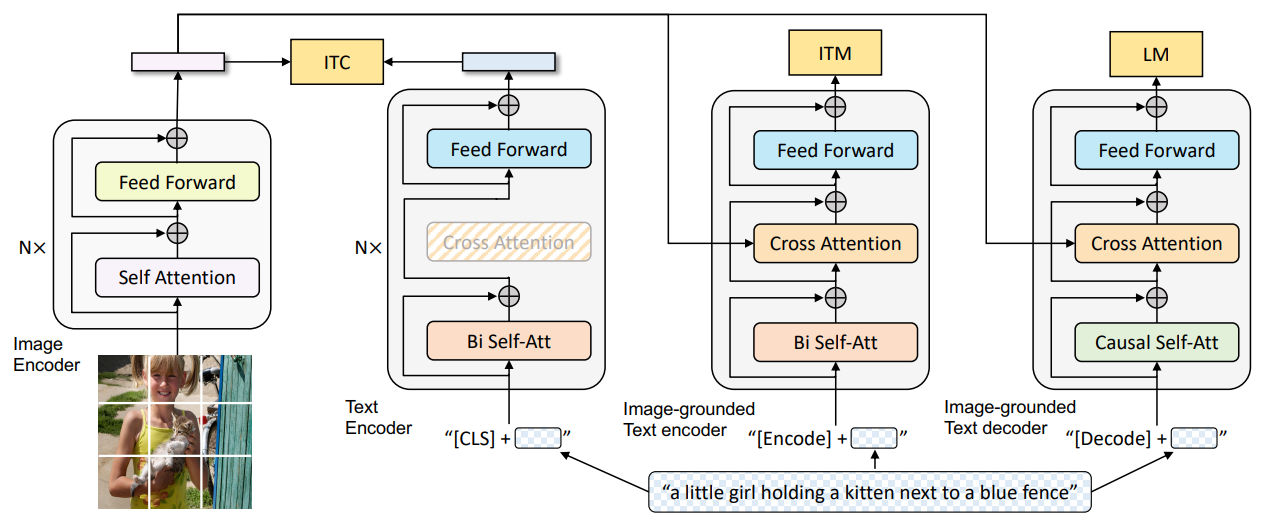
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Retrieval | 15 | 10.95% |
| Image Captioning | 12 | 8.76% |
| Language Modelling | 8 | 5.84% |
| Question Answering | 8 | 5.84% |
| Visual Question Answering | 7 | 5.11% |
| Visual Question Answering (VQA) | 7 | 5.11% |
| Image Generation | 6 | 4.38% |
| Large Language Model | 4 | 2.92% |
| Image Retrieval | 4 | 2.92% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
