TTD: Text-Tag Self-Distillation Enhancing Image-Text Alignment in CLIP to Alleviate Single Tag Bias
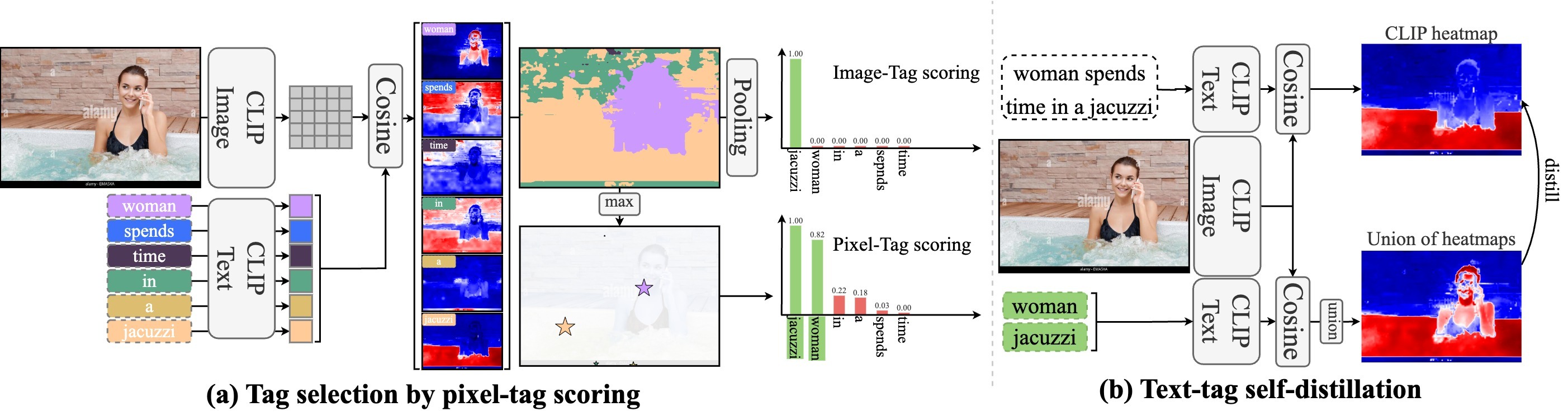
We identify a critical bias in contemporary CLIP-based models, which we denote as single tag bias. This bias manifests as a disproportionate focus on a singular tag (word) while neglecting other pertinent tags, stemming from CLIP's text embeddings that prioritize one specific tag in image-text relationships. When deconstructing text into individual tags, only one tag tends to have high relevancy with CLIP's image embedding, leading to biased tag relevancy. In this paper, we introduce a novel two-step fine-tuning approach, Text-Tag Self-Distillation (TTD), to address this challenge. TTD first extracts image-relevant tags from text based on their similarity to the nearest pixels then employs a self-distillation strategy to align combined masks with the text-derived mask. This approach ensures the unbiased image-text alignment of the CLIP-based models using only image-text pairs without necessitating additional supervision. Our technique demonstrates model-agnostic improvements in multi-tag classification and segmentation tasks, surpassing competing methods that rely on external resources. The code is available at https://github.com/shjo-april/TTD.
PDF AbstractCode


Datasets
Introduced in the Paper:
CC3M-TagMaskUsed in the Paper:
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
 COCO-Stuff
COCO-Stuff
 PASCAL VOC
PASCAL VOC
Results from the Paper
 Ranked #1 on
Open Vocabulary Semantic Segmentation
on COCO-Stuff-171
(mIoU metric)
Ranked #1 on
Open Vocabulary Semantic Segmentation
on COCO-Stuff-171
(mIoU metric)
